American Red Cross International Services Division continues their development of Portable OpenStreetMap, or POSM, in the latest 0.9 release. The concept is simple: use the full ecosystem of OpenStreetMap tools and sibling projects to deliver better geospatial data for aid and recovery wherever Red Cross goes.
In the case of integration of OpenDroneMap, the challenge has been one of compute power: how does one, for example, travel to a response in the Philippines, collect all the aerial data, and deliver those data to partners before departure?
The new answer? A passel of POSM. Well, we won’t do the story justice, so we’ll link out to the post:
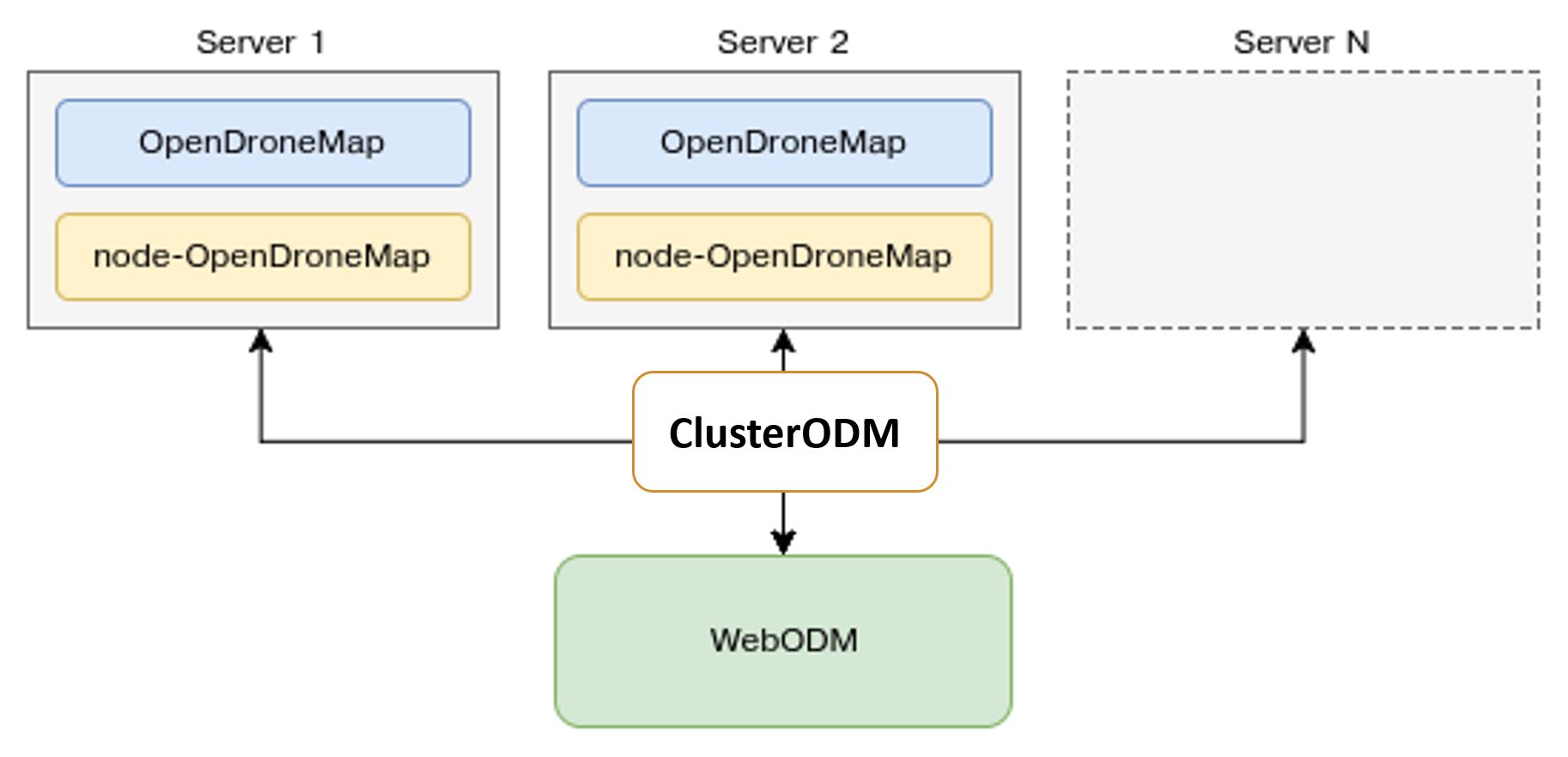
In a previous post, we discussed distributed split merge using ClusterODM an API proxy for NodeODM and NodeMICMAC. This was an exciting development, but we’ve taken it further with autoscaling. Autoscaling will allow you to deploy as many instances as you need to get the processing done on the provider of your choice. This currently works for n=1 providers (DigitalOcean). Want to help with others? We have issues open for AWS and Scaleway, or open an issue for another provider you want to see.
This means, no more parallel shells to get your data processed, just configure, send a job, and watch the data process.
How does this work? We need to configure a few pieces, I’ll give you the overview:
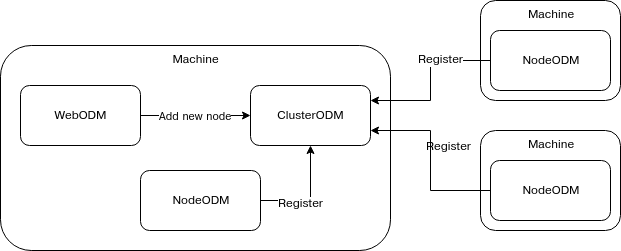
We need 3 elements: ClusterODM, a local NodeODM instance, and a configuration file so that ClusterODM can orchestrate deployment of the secondary servers.
Grab a decent size Digital Ocean machine to install this on, say something with 16 or 32 GB RAM. ClusterODM setup is easy, just follow these directions for dependencies. I’ll give you the crib notes: it’s just docker, docker-machine and NodeJS.
We’ll need to deploy a NodeODM instance locally. This does the local processing and also allows ClusterODM to know what API it is proxying. We need to run it on something other than the default port 3000
docker run -d -p 3001:3001 opendronemap/nodeodm:smimprov --port 3001
Now that we have a NodeODM instance, let’s proxy it with ClusterODM. Let’s create a configuration file for our ClusterODM:
Ok. Now we are ready for fun. We could connect WebODM to this, but I find it more convenient to do this on the command line. I’ll change directory into one level up from my images directory and then:
docker run -ti -v "$(pwd)/images:/code/images" opendronemap/odm --split 2500 --sm-cluster http://youriphere:3000
Code/community sprints are a fascinating energy. Below, we can see a bunch of folks laboring away at laptops scattered through the room at the OSGeo’s 2019 Community Sprint, an exercise in a fascinating dance of introversion and extroversion, of code development and community collaboration.
A portion of the OpenDroneMap team is here for a bit working away at some interesting opportunities. Tonight, I want to highlight an extension to work mentioned earlier on split-merge: distributed split-merge. Distributed split-merge leverages a lot of existing work, as well as some novel and substantial engineering solving the problem of distributing the processing of larger datasets among multiple machines.
Image of the code sprint.
This is, after all, the current promise of Free and Open Source Software: scalability. But, while the licenses for FOSS allow for this, a fair amount of engineering goes into making this potential a reality. (HT Piero Toffanin / Masserano Labs) This also requires a new / modified project: ClusterODM, a rename and extension of MasseranoLabs NodeODM-proxy. It requires several new bits of tech to properly distribute, collect, redistribute, then recollect and reassemble all the products.
Piero Toffanin with parallel shells to set up multiple NodeODM instances
————————————————————————————————–
“Good evening, Mr. Briggs.”
The mission: To process 12,000 images over Dar es Salaam, Tanzania in 48 hours. Not 17 days. 2 days. To do this, we need 11 large machines (a primary node with 32 cores and 64GB RAM and 10 secondary nodes with 16 cores and 32GB RAM), and a way to distribute the tasks, align the tasks, and put everything back together. Something like this:
… just with a few more nodes.
Piero Toffanin and India Johnson working on testing ClusterODM
This is the second dataset to be tested on distributed split-merge, and the largest to be processed in OpenDroneMap to a fully merged state. Honestly, we don’t know what will happen: will the pieces process successfully and successfully stitch back together into a seamless dataset? Time will tell.
For the record, the parallel shells were merely for NodeODM machine setup.